
Algorithm 头文件#
C++的算法头文件中有很多实用的函数
排序#
sort():对容器中的元素进行排序。依次传入三个参数,要排序区间的起点,要排序区间的终点+1,比较函数。比较函数可以不填,则默认为从小到大排序。
也可以使用greater<type>()来实现从大到小排序,或者自定义比较函数。
#include<bits/>stdc++.h>
using namespace std;
int a[105];
int main(){
int n;
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%d",&a[i]);
}
sort(a,a+n);
for(int i=0;i<n;i++){
printf("%d ",a[i]);
}
return 0;
}
查找#
lower_bound():查找第一个大于等于 x 的数的位置。传入三个参数,要查找区间的起点,要查找区间的终点+1,x。返回值为指向第一个大于等于 x的数的迭代器。
upper_bound():查找第一个大于 x 的数的位置。传入三个参数,要查找区间的起点,要查找区间的终点+1,x。返回值为指向第一个大于 x的数的迭代器。
在从小到大的排序数组中: 两者都是利用二分查找实现的,时间复杂度为 O(logn)。从
begin位置开始查找,直到end-1位置结束,不存在返回end。在从大到小的排序数组中:
lower_bound(begin,end,num,greater<type>())upper_bound(begin,end,num,greater<type>())
#include<bits/stdc++.h>
using namespace std;
int cmp(int a,int b){
return a>b;
}
int main(){
int num[6]={1,2,4,7,15,34};
sort(num,num+6); //按从小到大排序
int pos1=lower_bound(num,num+6,7)-num;
//返回数组中第一个大于或等于被查数的值
int pos2=upper_bound(num,num+6,7)-num;
//返回数组中第一个大于被查数的值
cout<<pos1<<" "<<num[pos1]<<endl;
cout<<pos2<<" "<<num[pos2]<<endl;
sort(num,num+6,cmp); //按从大到小排序
int pos3=lower_bound(num,num+6,7,greater<int>())-num;
//返回数组中第一个小于或等于被查数的值
int pos4=upper_bound(num,num+6,7,greater<int>())-num;
//返回数组中第一个小于被查数的值
cout<<pos3<<" "<<num[pos3]<<endl;
cout<<pos4<<" "<<num[pos4]<<endl;
return 0;
}
优先队列#
priority_queue:优先队列,默认是大根堆。可以使用greater<type>()来实现小根堆。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | push(val) | 插入元素并维护堆序 |
| 删除元素 | pop() | 删除堆顶(最大或最小) |
| 访问元素 | top() | 访问当前优先级最高的元素 |
| 其他功能 | empty() / size() | 容器状态 |
| 遍历方式 | ❌ | 不支持遍历(非线性结构) |
| 默认特性 | 最大堆 | 使用 < 比较,最大值优先 |
| 自定义优先级 | 使用 greater<type> | 构造最 |
#include<bits/stdc++.h>
#include<queue>
using namespace std;
int main(){
priority_queue<int> q; //优先队列
q.push(1);
q.push(2);
q.push(3);
while(!q.empty()){
cout<<q.top()<<" "; //输出队列中最大的数
q.pop(); //删除队列中最大的数
}
return 0;
}
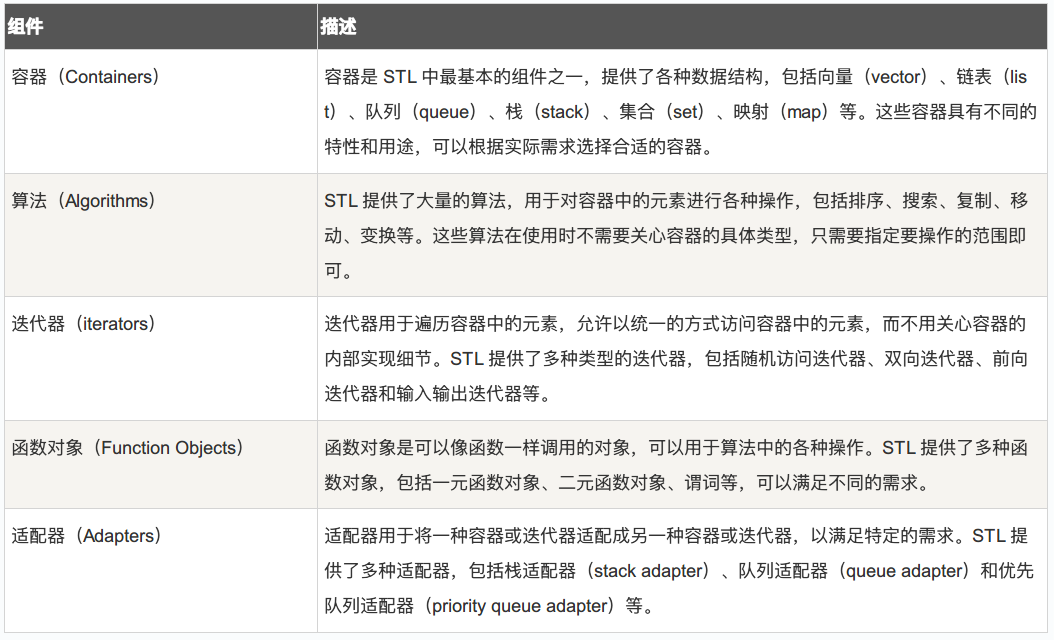
STL 模版使用#
C++的 STL(标准模板库)是一个强大的工具,提供了许多数据结构和算法的实现。STL 的使用可以大大简化代码,提高开发效率。
vector#
通过vector<int> v可以实现一个储存整数的空的动态数组,支持随机访问。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | push_back(val) | 在末尾插入元素 |
insert(pos, val) | 在指定位置插入元素 | |
| 删除元素 | pop_back() | 删除末尾元素 |
erase(pos) | 删除指定位置的元素 | |
clear() | 清空容器 | |
| 查找元素 | find(vec.begin(), vec.end(), val) | 线性查找元素 |
| 访问元素 | vec[i] / at(i) | 访问第 i 个元素 |
| 其他功能 | size() / empty() | 获取大小 / 判断是否为空 |
| 随机访问支持 | ✅ | 常数时间访问 |
#include<iostream>
#include<vector>
using namespace std;
int main(){
vector<int> v; //创建一个空的动态数组}
for(int i=0;i<10;i++){
v.push_back(i); //向数组中添加元素
}
for(int i=0;i<v.size();i++){
cout<<v[i]<<" "; //输出数组中的元素
}
return 0;
}
list#
通过 list<int> L 来定义一个空的 list。当然 list 可以存任何类型的数据,比如 list<string> L 等等。
list 是一个双向链表,支持在任意位置插入和删除元素,适合频繁的插入和删除操作。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | push_back(val) / push_front(val) | 在末尾或开头插入元素 |
insert(pos, val) | 在指定位置插入元素 | |
| 删除元素 | pop_back() / pop_front() | 删除末尾或开头元素 |
erase(pos) | 删除指定位置的元素 | |
remove(val) | 删除所有值为 val 的元素 | |
| 查找元素 | find(list.begin(), list.end(), val) | 线性查找元素 |
| 访问元素 | 只能通过迭代器访问 | 不支持下标 |
| 其他功能 | size() / empty() | 获取大小 / 判断是否为空 |
| 随机访问支持 | ❌ | 不支持下标访问 |
#include <iostream>
#include <list>
using namespace std;
int main() {
list<int> L; // 定义一个空的 list
for (int i = 0; i < 10; i++) {
L.push_back(i); // 向 list 中添加元素
}
for (list<int>::iterator it = L.begin(); it != L.end(); it++) {
cout << *it << " "; // 输出 list 中的元素
}
cout << endl;
return 0;
}
queue#
通过 queue<int> q 来定义一个储存整数的空的 queue。当然 queue 可以存任何类型的数据,比如 queue<string> q 等等。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | push(val) | 入队(尾部插入) |
| 删除元素 | pop() | 出队(移除队首) |
| 访问元素 | front() / back() | 获取队首 / 队尾元素 |
| 其他功能 | empty() / size() | 判断是否为空 / 获取大小 |
| 遍历方式 | ❌ | 不支持直接遍历 |
| 顺序特性 | 先进先出(FIFO) | 队列结构特性 |
#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> q;//定义一个队列
q.push(1);//入队
q.push(2);
q.push(3);
while (!q.empty()) {//当队列不为空
cout << q.front() << endl;//取出队首元素
q.pop();//出队
}
return 0;
}
stack#
通过 stack<int> S 来定义一个全局栈来储存整数的空的 stack。当然 stack 可以存任何类型的数据,比如 stack<string> S 等等。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | push(val) | 入栈(压栈) |
| 删除元素 | pop() | 出栈(仅移除顶部元素) |
| 访问元素 | top() | 查看栈顶元素 |
| 其他功能 | empty() / size() | 判断是否为空 / 获取元素个数 |
| 遍历方式 | ❌ | 不支持直接遍历 |
| 顺序特性 | 后进先出(LIFO) | 栈的基本结构 |
#include <iostream>
#include <stack>
using namespace std;
stack<int> S;//定义一个栈
int main(){
S.push(1); //入栈
S.push(20);
S.push(16);
while(!S.empty()){ //当栈不为空
cout<<S.top()<<endl; //取出栈顶元素
S.pop(); //出栈
}
return 0;
}
map#
通过 map<string, int> dict 来定义一个 key: value 映射关系的空的 map。当然 map 可以存任何类型的数据,比如 map<int, int> m 等等。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | map[key] = val / insert({key, val}) | 插入键值对(自动排序) |
| 删除元素 | erase(key) | 删除指定键 |
| 查找元素 | find(key) | 二叉搜索查找,O(log n) |
| 访问元素 | map[key] | 若不存在会创建新键 |
| 其他功能 | size() / empty() | 容器信息 |
| 自动排序 | ✅ | 按 key 升序排列 |
| 键唯一性 | ✅ | 不允许重复 key |
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
map<string,int> dict; //定义一个空的map
string key;
int value;
for(int i=0;i<5;i++){
cin >> key >> value; //输入键值对(这样赋值)
dict[key]=value; //将键值对存入map中
}
/* 使用迭代器遍历map的key和value */
for(map<string,int>::iterator it = dict.begin();it != dict.end();it++){
cout << it->first << " " << it->second << endl; //输出键值对
}
/* 使用auto遍历map的key和value */
for(auto it = dict.begin();it != dict.end();it++){
cout << it->first << " " << it->second << endl; //输出键值对
}
dict.clear(); //清空map
return 0;
}
set#
通过 set<string> country 来定义一个空的存储字符串的 set。当然 set 可以存任何类型的数据,比如 set<int> s 等等。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | insert(val) | 插入自动排序的唯一元素 |
| 删除元素 | erase(val) | 删除指定元素 |
clear() | 清空容器 | |
| 查找元素 | find(val) | 二叉搜索查找,O(log n) |
| 访问元素 | 只能通过迭代器 | 无下标访问 |
| 其他功能 | size() / empty() | 容器信息 |
| 自动排序 | ✅ | 升序排序 |
| 元素唯一性 | ✅ | 不允许重复元素 |
#include <iostream>
#include <set>
#include <string>
using namespace std;
int main() {
set<string> country; // 定义一个空的 set
string name;
// 输入字符串并存入 set 中
for (int i = 0; i < 5; i++) {
cin >> name;
country.insert(name);
}
// 使用迭代器遍历 set 的元素
for (set<string>::iterator it = country.begin(); it != country.end(); it++) {
cout << *it << endl; // 输出 set 中的元素
}
// 使用 auto 遍历 set 的元素
for (auto it = country.begin(); it != country.end(); it++) {
cout << *it << endl; // 输出 set 中的元素
}
// 删除 set 中的元素
country.erase("China");
// 使用 find() 函数查找 set 中的元素
set<string>::iterator it = country.find("China");
// 统计 set 中元素的个数
cout << country.count("China") << endl; // 输出 set 中元素的个数
// 使用 empty() 函数判断 set 是否为空
cout << country.empty() << endl; // 输出 set 是否为空
// 输出 set 中元素的
cout << country.size() << endl; // 输出 set 中元素的个数
使用 clear() 函数清空 set
country.clear();
return 0;
}
unordered_map#
通过 unordered_map<string, int> dict 来定义一个 key: value 映射关系的空的 unordered_map。当然 unordered_map 可以存任何类型的数据,比如 unordered_map<int, int> m 等等。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | umap[key] = val / insert({key, val}) | 插入键值对(无序) |
| 删除元素 | erase(key) | 删除指定键 |
| 查找元素 | find(key) | 哈希查找,平均 O(1) |
| 访问元素 | umap[key] | 若不存在会创建新键 |
| 其他功能 | size() / empty() | 容器信息 |
| 自动排序 | ❌ | 无序存储 |
| 键唯一性 | ✅ | 不允许重复 key |
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main(){
unordered_map<string,int> dict; //定义一个空的unordered_map
string key;
int value;
for(int i=0;i<5;i++){
cin >> key >> value; //输入键值对(这样赋值)
dict[key]=value; //将键值对存入unordered_map中
}
/* 使用迭代器遍历unordered_map的key和value */
for(auto it = dict.begin();it != dict.end();it++){
cout << it->first << " " << it->second << endl; //输出键值对
}
dict.clear(); //清空unordered_map
return 0;
}
unordered_set#
与 set/multiset 的区别在于元素无序,只关心 「元素是否存在」,使用哈希实现。
| 操作类别 | 方法/函数 | 说明 |
|---|---|---|
| 插入元素 | insert(val) | 插入元素(无序,不重复) |
| 删除元素 | erase(val) | 删除指定元素 |
| 查找元素 | find(val) | 平均 O(1) 查找 |
| 判断存在 | count(val) | 判断元素是否存在(0 或 1) |
| 遍历元素 | 使用 for (auto x : uset) | 无序遍历 |
| 其他功能 | size() / empty() | 获取大小 / 判空 |
| 元素唯一性 | ✅ | 不允许重复元素 |
| 自动排序 | ❌ | 无序结构,基于哈希表 |
共有函数#
以下是 STL 容器中常用的共有函数:
=:赋值运算符以及复制构造函数。begin():返回指向容器开头元素的迭代器。end():返回指向容器末尾下一个位置的迭代器(不指向具体元素)。size():返回容器中元素的个数。max_size():返回容器理论上能存储的最大元素个数(依赖容器类型和存储变量类型)。empty():判断容器是否为空。swap():交换两个容器的内容。clear():清空容器中的所有元素。- 比较运算符:
==/!=:判断两个容器是否相等或不等。</>/<=/>=:按字典序比较两个容器的大小(无序容器不支持这些运算符;map的每个元素相当于set<pair<key, value>>)。
一些注意点#
unordered_map和map的区别unordered_map 是无序的,基于散列表实现,适用于元素不需要有序,对于单次查询时间不敏感的场景;
map 是有序的,基于红黑树实现,适用于元素需要有序,对于单次查询时间较为敏感的场景;
- 需要保持 key 的有序性:
map<string, int> student_scores; - 需要做范围查找或区间查询:
map<int, string> intervals; auto it = intervals.lower_bound(10); // 找到大于等于 10 的最小键- 频繁遍历时需要有序输出:
map<int, string> log_by_time; // 按时间戳排序的日志- 需要保持 key 的有序性:
unordered_map 的查找速度比 map 快,但是 unordered_map 占用的内存比 map 多。
迭代器的使用 在 STL 中迭代器的行为模式与指针类似,迭代器可以用来遍历容器中的元素。 主要支持两个运算符:自增(++)和解引用(*)。
vector<int> data(10); for (int i = 0; i < data.size(); i++) cout << data[i] << endl; // 使用下标访问元素 for (vector<int>::iterator iter = data.begin(); iter != data.end(); iter++) cout << *iter << endl; // 使用迭代器访问元素 // 在C++11后可以使用 auto iter = data.begin() 来简化上述代码auto关键字auto关键字用于自动推导变量类型,简化代码书写。可以用于声明变量、函数返回值等场景。属于 C++11 标准。但是使用时要注意以下几点:auto只能用于局部变量,不能用于全局变量。auto不能用于函数参数和返回值。auto不能用于数组和函数指针。auto不能用于引用类型。auto不能用于 const 和 volatile 类型。auto不能用于模板参数。