
0 前言#
最近做了一个 Agent 项目,我越来越觉得:命令行形式天然适合 Agent 交互与处理,恰如把一个二维的 GUI 应用压扁成一维的命令行。
这当然也是最近很热门的方向。像 HKU 黄超老师做的 CLI-Anything,就是一个很好的例子。仔细想来,很多爆发性的热点,往往底层想法都很简单。
钉钉、飞书,甚至网易云都发布了 CLI,这个世界的任何行业都想和 AI 绑上关系 😂 古老的命令行宣布着:“GUI 将死,CLI 才是未来。”
1 钉钉和飞书的 CLI#
1.1 钉钉的 CLI#
钉钉做的事情是重写底层代码,把整个产品 CLI 化。它并不是在现有 GUI 上包一层壳,而是让 Agent 直接调用底层能力,绕过图形界面。
钉钉的命令结构是标准的“服务 / 资源 / 动作”三级,比如 dws calendar event create,并且在面向 Agent 的场景里做了一些设计细节,比如 --yes、--mock、--dry-run 等参数。
在安全方面,钉钉做了三件事:无感认证(Agent 自动继承企业权限)、批量熔断(防止 Agent 失控批量操作)、安全沙箱(限制 Agent 的权限范围)。
1.2 飞书的 CLI#
飞书的命令体系是三层设计:
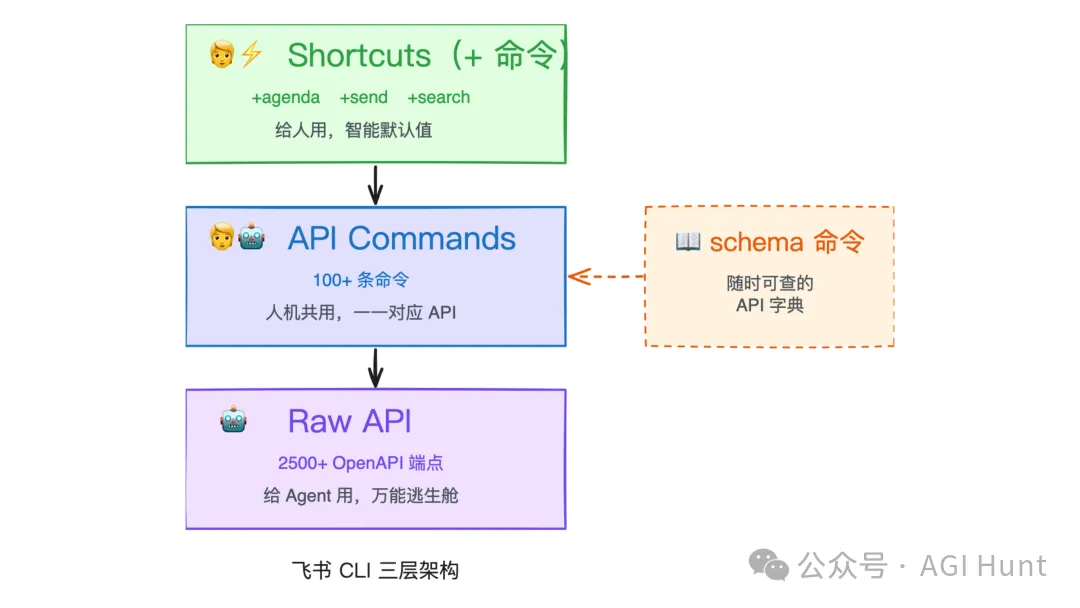
第一层:Shortcuts(
+前缀命令),面向人类这是飞书最有辨识度的设计。所有快捷命令都带
+前缀,并且内置智能默认值:lark-cli calendar +agenda # 看今天日程 lark-cli im +messages-send --text "hello" --chat-id oc_xxx lark-cli contact +search-user --query "John" lark-cli docs +fetch --doc-id xxx这些命令做了很多参数简化。比如
+messages-send支持--text、--markdown、--image、--file这类直接参数,不需要自己拼 JSONcontent body。第二层:API Commands,面向人类和 Agent
有 100 多条命令,和飞书平台 API 一一对应。
第三层:Raw API,面向 Agent
这一层直接调用飞书底层 2500 多个 OpenAPI 端点,相当于一个“万能逃生舱”。不管飞书有什么 API,即使 CLI 没有封装对应的命令,Agent 也能直接调,从而避免在边缘场景中被卡住。
同时,飞书还内置了一个
schema命令,可以查看任意 API 方法的参数、类型和所需权限。
用一个比喻来说,钉钉 CLI 像是给企业行政部门配的数字助理,而飞书 CLI 更像是给研发团队配的效率工具。
2 为什么是 CLI?#
ScaleKit 做过一组 benchmark,对 GitHub 官方 MCP 服务器和 gh CLI 做了一组对照实验,测试模型是 Claude Sonnet 4。
- 查一个仓库用什么语言,CLI 消耗 1,365 tokens,MCP 消耗 44,026 tokens。
- 查 PR 详情和审核状态,CLI 消耗 1,648 tokens,MCP 消耗 32,279 tokens,接近 20 倍。
- 查仓库元数据和安装方式,CLI 消耗 9,386 tokens,MCP 消耗 82,835 tokens,接近 9 倍。
但问题是:CLI 调 API 如果认真做安全,你最终还是得补上 OAuth 授权、动态客户端注册、敏感操作审批、服务端鉴权……加完这些,你其实又重新发明了 MCP。
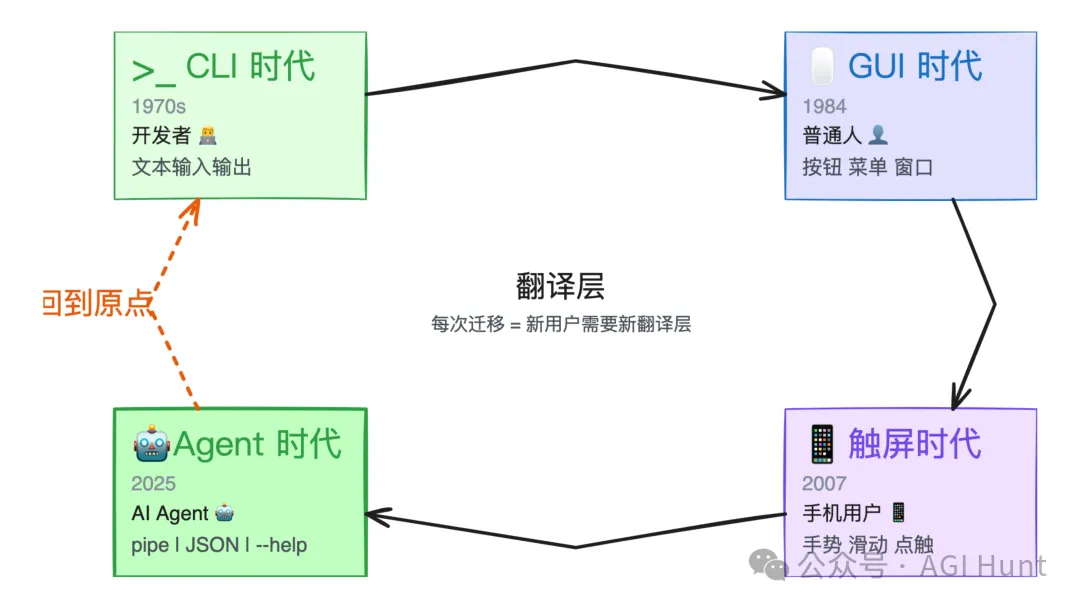
这篇公众号还描述了一个“第四次迁移”的框架:大型机 → PC → 移动 → Agent。每一次迁移,本质上都是因为出现了新的用户。普通人不会打命令,所以有了 GUI;手机用户不方便用鼠标,所以有了触屏。
现在又来了一种新用户:AI Agent。
CLI 是 LLM 的母语,MCP 是后天学的外语。
所以,GUI Agent 是否已经是一个伪命题?
3 给 Agent 设计 CLI 的 N 条原则#
不同于传统的 CLI 设计规范(面向人类用户),面向 Agent 的 CLI 设计需要考虑它完全不同的认知特点和失败模式。
Agent 是怎么想的?#
Agent 天生就对命令行有相当强的直觉。 LLM 的训练数据里有大量 shell 命令和 bash 脚本,它们分布在 GitHub 代码、Stack Overflow 问答、Linux 文档、在线教程等各种来源中。
但这种直觉也是有边界的。 现在的模型在使用 CLI 时,通常还是跑 --help、解析输出、拼接命令、看退出码。模型能力的提升当然会让每一步判断更准确,但如果 CLI 本身设计得不好,再强的模型也会一样掉进坑里。
好的 Agent 会区分“观察到的事实”和“猜测”,先验证假设,再采取行动;差的 Agent 会把猜测当事实,然后一路错下去。
Agent 怕什么?#
Agent 在使用 CLI 时有几个天然弱点:
- 大小写敏感的短参数。像
grep、ssh这类工具的短参数,Agent 很容易搞混,导致命令执行失败,因为它本质上是在做概率选择。 - 交互式提示。Agent 没法回答
Are you sure? [y/N]这种问题。 - 幻觉参数。Agent 会很自信地使用并不存在的参数。
- 非结构化输出。给 Agent 一段 JSON,它能立刻提取字段、做条件判断、做管道传递;给它一段人类可读的 table 输出,它就只能靠猜。
4 十条设计原则#
原则一:名词在前#
命令结构应该采用 noun-verb(名词-动词),而不是 verb-noun(动词-名词)。
# 好:noun-verb
docker container ls
gh pr create
lark-cli calendar +agenda
dws contactuser search
# 不好:verb-noun
create-pr
delete-image
search-user
为什么?因为 Agent 发现命令的过程,本质上是一个树搜索。
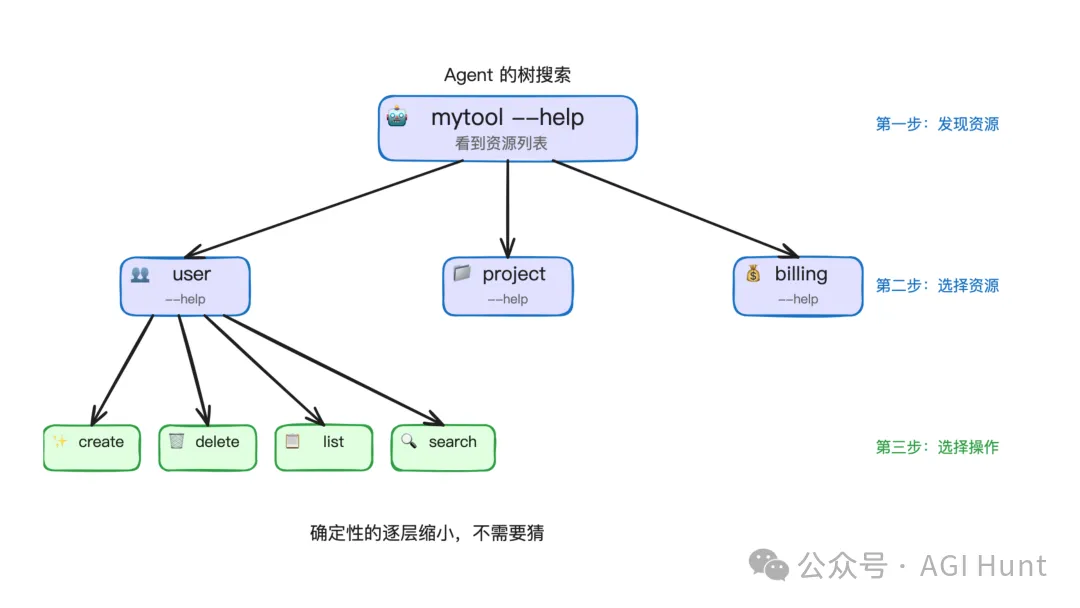
它会先跑 mytool --help,看到有 user、project、billing 三个名词;然后再跑 mytool user --help,看到 create、delete、list、search。
这是一个确定性的、逐层缩小范围的过程。Agent 不需要猜,每一步都有 --help 可以查。
而 verb-noun 结构(create-user、create-project、create-billing)把所有操作平铺在一层,Agent 面对的是一个巨大的扁平列表,没有层级引导。
Docker 的设计就是典范:container、image、volume、network 是名词,ls、rm、create、inspect 是动词。同一个动词在不同名词下语义保持一致。Agent 只要学会了 docker container ls,就能推断出 docker volume ls。
Linus 说过:“好的代码不是简洁,而是重新概念化问题本身,让特殊情况消失在一般情况中。”
noun-verb 结构做的正是这件事:让每个新命令都只是已有模式的自然延伸,不再有特殊情况。
原则二:长参数优先#
所有参数都应该有长格式(如 --verbose),短格式(如 -v)只能作为可选的人类便利。
这条规则对人类来说是建议,对 Agent 来说几乎应该算是硬性要求。
第一,长参数具备语义自描述能力。--dry-run 这个词本身就在告诉 Agent 它的功能:预演、试运行。而 -n 在部分工具里虽然等同于 --dry-run,但本身完全没有自描述能力。
第二,长参数可以消除歧义。-v 在很多工具里表示 verbose,但 -V 往往表示 version。一个字母的大小写差异,就可能改变全部含义;--verbose 和 --version 之间则几乎不会混淆。
第三,长参数更符合 LLM 的统计优势。模型在训练数据里见过无数次 --output,它和“指定输出位置”之间的语义绑定已经被反复强化;而 -o 的语义绑定要弱得多,在不同工具中甚至可能完全不同。
钉钉 CLI 有个设计值得注意:它的 --yes 参数描述是“跳过确认提示(AI Agent 模式)”。参数名本身就是自描述的,Agent 一看就知道什么时候该加它。
多花几个 token 去写长参数,换来的是明显更低的出错概率。对 Agent 来说,一次错误执行带来的修复成本,远高于多花几个 token 的开销。
原则三:结构化输出#
# stdout 输出 JSON 数据
mytool user list --format json
# stderr 输出人类可读的状态信息
# 二者严格分流
stdout 和 stderr 必须严格分离。JSON 数据走 stdout,进度条、警告、日志全走 stderr。这样 Agent 才能安全地用管道处理,而不用担心非 JSON 内容污染数据流。
GitHub CLI 在这方面做得很出色:检测到输出被管道传输时,会自动切换为 tab 分隔格式,去掉颜色转义符,并避免文本截断。飞书 CLI 也支持 JSON、NDJSON、table、CSV、pretty 五种格式,覆盖面很全。
但这里有一个很容易被忽略的点:结构化输出一旦发布,本质上就是 API。Kubernetes 在 v1.14 弃用 --export,又在 v1.18 正式移除,结果数千个 Helm chart 和 CI/CD 管道直接受影响,因为下游已经依赖了这个输出格式。
加一个新的可选字段,通常是安全的;改变已有字段的类型或名称,就是破坏性变更。CLI 输出的 schema,应该像 REST API 版本一样被严肃对待。
原则四:感知环境#
CLI 应该检测自己运行在终端(TTY)还是管道(pipe)中,并自动调整行为。
# 终端中:彩色输出、表格、进度条
mytool status
# 管道中:纯文本、JSON、无颜色、无交互
mytool status | jq '.'
Agent 几乎永远是在非 TTY 环境中调用 CLI 的。如果你的 CLI 在非 TTY 时还弹确认框、显示 spinner、输出 ANSI 颜色码,Agent 就会卡住,或者解析出错。
GitHub CLI 的做法值得参考:非 TTY 时自动使用 tab 分隔、去颜色、不截断。钉钉 CLI 的 --yes 参数也是为此设计的,用来跳过所有确认提示,进入 AI Agent 模式。
gcloud 文档里有一句值得所有 CLI 开发者记住的话:“不要依赖 gcloud 的原始输出格式,永远使用 --format 标志。” 因为原始输出格式可能随着版本变化。
更进一步的做法是:CLI 在非 TTY 环境下默认输出 JSON,而不应该要求 Agent 额外再加 --json。飞书 CLI 的格式解析逻辑就接近这个思路:先看 --json 标志,再看 TTY 状态;非 TTY 下自动降级为 JSON。
原则五:干跑优先#
每个会产生副作用的命令,都应该支持 --dry-run。
从 Agent 的角度看,--dry-run 提供了一个低成本的试错机制。
Agent 不确定一条命令会产生什么后果时,可以先用 --dry-run 看看;看到预览结果后,再决定是否真正执行。这本质上是给了 Agent 一个“探索 - 验证”的反馈循环,而不是一上来就赌博。
钉钉和飞书 CLI 都支持 --dry-run。飞书的实现更细致一些:干跑时会输出完整的请求 URL、方法和参数,Agent 可以在执行前确认请求是否正确。
Lightning Labs 的设计更进一步:--dry-run 使用专门的退出码(exit code 10),这样 Agent 可以通过退出码区分“干跑成功”和“真正执行成功”。
好的 --dry-run 输出最好是结构化的 JSON diff,明确告诉 Agent 会创建、修改还是删除什么。只输出一句“这是干跑模式”,远远不够。
原则六:退出码控制#
退出码对人类来说往往是可忽略的细节,但对 Agent 来说,退出码本身就是控制流。
Agent 执行完一条命令后,它看到的第一个信号通常不是输出内容,而是退出码。退出码会直接决定它的下一步:成功了就继续走管道,失败了就进入错误处理。
只用 0 和 1 远远不够。Agent 需要更细的粒度来区分失败类型:
| 退出码 | 含义 | Agent 行为 |
|---|---|---|
| 0 | 成功 | 继续执行管道 |
| 1 | 一般错误 | 读 stderr 诊断 |
| 2 | 参数失败 | 修正参数重试 |
| 3 | 资源不存在 | 跳过或创建 |
| 4 | 权限不足 | 提示用户授权 |
| 5 | 冲突/已存在 | 跳过或更新 |
关键要求是:退出码必须跨版本保持稳定。退出码一旦发布,就是契约的一部分;改变退出码的含义,和改变 API 返回值一样危险。
原则七:防住幻觉#
前沿模型的幻觉率确实下降了很多,但这不意味着你的 CLI 可以不设防。
原因很简单:输入验证本来就是基本的安全实践,不管调用方是人还是 Agent。你不会因为“大部分用户都是好人”就取消 SQL 注入防护,同样也不该因为“新模型不太幻觉了”就放松输入校验。
输入验证必须严格。Lightning Labs 的做法很值得学习:验证 URL(拒绝 javascript:、file: 协议和嵌入凭据的 URL)、验证域名(拒绝路径分隔符和 shell 元字符)、验证输出路径(拒绝向 .ssh/、.gnupg/ 等敏感目录写入)。
能用枚举约束的参数,就不要用自由文本。--format json|table|csv 明显比 --format <string> 安全,因为 Agent 在受限选项空间里犯错的概率会小很多。Anthropic 的 tool use 文档也推荐类似策略。
同时,CLI 最好提供 schema 自省能力,让 Agent 能查询工具自身的能力:
mytool schema --all # 输出完整命令树的 JSON
mytool schema user create # 输出某个命令的参数定义
飞书 CLI 已经实现了这个能力:lark-cli schema calendar.events.list --format pretty 可以输出任意 API 方法的参数、类型和所需权限。对 Agent 来说,这相当于一本随时可查的字典,比在训练数据里碰运气靠谱得多。
这里还有个反直觉的点:schema 自省应该按需查询,而不是一股脑把所有 schema 都塞进上下文。
Agent 对常用命令通常已经有很强的统计记忆,过量文档反而会干扰判断。这也是 CLI 相比 MCP 的核心优势之一:MCP 往往会把所有工具 schema 一次性注入上下文,而 CLI 则允许 Agent 按需跑 --help,只读取眼前这一条命令的说明。
原则八:幂等设计#
能用声明式,就尽量别用命令式。
# 命令式:资源已存在会报错
mytool user create --name "john"
# 声明式:无论调用多少次,结果一致
mytool user ensure --name "john"
# 或
mytool user create --name "john" --if-not-exists
Agent 会重试。网络超时了会重试,上一次执行结果不确定了会重试,任务中断恢复后也可能继续重试。如果命令不是幂等的,那么重试就可能导致两个重复用户、两封重复邮件,甚至更糟。
kubectl apply 就是声明式设计的教科书案例:定义期望状态,Kubernetes 负责协调实际状态。不管 Agent 跑多少次 kubectl apply -f deployment.yaml,结果都一致。
飞书 CLI 的 +messages-send 支持 --idempotency-key 参数,也属于这个思路:Agent 传入一个唯一标识符,即使命令被重复执行,服务端也只处理一次。这个设计值得在更多命令里推广。
原则九:错误即指南#
Agent 犯错之后,错误信息往往是它唯一的修复依据。
{
"error": "permission_denied",
"message": "缺少 calendar:read 权限",
"suggestion": "运行 lark-cli auth login --domain calendar 完成授权",
"retryable": false
}
好的错误信息应该至少包含四个要素:错误类型(机器可读,便于 Agent 判断是重试还是放弃)、具体描述(到底发生了什么)、修复建议(下一步该怎么做)、是否可重试(网络超时值得重试,权限不足通常不值得)。
飞书 CLI 在权限不足时会自动告诉你缺什么权限、该如何补齐,这对 Agent 非常友好。
还记得前面提到的那个 693 行幻觉案例吗?模型连续 22 轮坚持自己的方案是对的,却没有根据错误反馈调整方向。错误信息如果足够强,就能迫使 Agent 重新审视自己的判断。
原则十:帮助即大脑#
最后一条,也是最重要的一条。
Anthropic 的 tool use 文档里反复强调一个发现:“描述是影响工具使用准确率的最关键因素。” 他们仅仅通过优化工具描述,就在 SWE-bench 上显著降低了错误率、提高了完成率。
映射到 CLI,--help 的质量几乎直接决定了 Agent 的表现。
好的 --help 应该做到:
- 以示例开头。
clig.dev的建议是:用户(包括 Agent)看到帮助文本时,第一眼找的是示例。最常用的 2 到 3 个示例,应该放在最前面。 - 明确标注必需和可选。 比如
--chat-id <required>,或--format <optional, default: json>。Agent 需要知道哪些参数必须传。 - 参数描述包含值域。 不要只写
--format string,而要写--format json|table|csv。 - 保持简短。 过长的帮助文本反而会降低 Agent 的准确率。对常用命令来说,50 行以内通常更合适。
Checklist#
最后,我再给出一份可以直接拿去用的 checklist,供你在用 Claude Code / Codex 开发 CLI 时参考:
- 命令结构采用 noun-verb 层级,支持树搜索
- 所有参数都有长格式,短格式只作为可选便利
-
--json输出结构化数据到stdout,状态信息走stderr - 检测 TTY 状态,非 TTY 环境自动调整输出
- 所有副作用操作都支持
--dry-run,并输出结构化 diff - 退出码具备文档化的细粒度语义
- 参数尽量用枚举约束值域,并进行严格输入验证
- 支持 schema 自省命令
- 关键操作设计为幂等,或提供
--if-not-exists - 错误信息包含类型、描述、修复建议和可重试标志
-
--help以示例开头,标注必需 / 可选,并尽量控制在 50 行以内 - 提供
--yes/--no-interactive之类的参数,跳过所有交互式提示
这些原则来自 POSIX 标准、GNU 编码规范、clig.dev 社区指南、12 Factor CLI 框架、Anthropic 的 tool use 文档,以及钉钉和飞书 CLI 的实战检验。