
前言#
看到一篇很好的文章,作者质疑了多智能体系统的必要性,认为他们违背了认知可靠性的基本原理:
- 上下文碎片化悖论: LLMs 的决策质量与上下文完整性正相关。由于子代理缺失主代理的决策树,导致输出偏差。
- 决策熵增定律: 并行系统决策结点数与系统混乱度呈指数关系。多个子代理独立产生的设计决策很大概率发生协调冲突。
正好最近对群体智能很感兴趣,所以记录下。 Don’t Build Multi-Agents
Principles of Context Engineering#
当智能体(agent)需要长时间运行、保持逻辑连贯、持续完成复杂任务时,一个最核心的挑战就是防止错误的累积扩散。如果上下文管理不当,哪怕是微小的误解或遗漏,也会在系统中层层传递,最终导致整体崩溃。解决这一问题的根本方法,是构建强健的 “上下文工程” 机制。
曾经我们倡导提示词工程(Prompt Engineering),即用尽可能明确和优化的方式来编写输入,以引导模型输出理想结果,但是现在这还远远不够。 上下文工程(Context Engineering)是提示词工程的进化版本,不再只是写好 prompt,而是关注:
- 如何构建和维护一个强健的上下文系统,使得智能体能够在复杂任务中保持一致性和连贯性。
- 如何管理和优化上下文信息的流动,确保每个决策都基于完整和准确的信息。
- 如何让系统在动态环境下自动组合有效提示和状态,以适应不断变化的任务需求。
💡 简单说:Prompt Engineering 是对模型说话的艺术;Context Engineering 则是让模型真正“记住”和“理解”整个任务流程的科学。
举一个常见的代理类型:
- 将其工作分解为多个子任务
- 启动子代理来处理这些部分
- 最终将子代理的结果合并成一个完整的输出
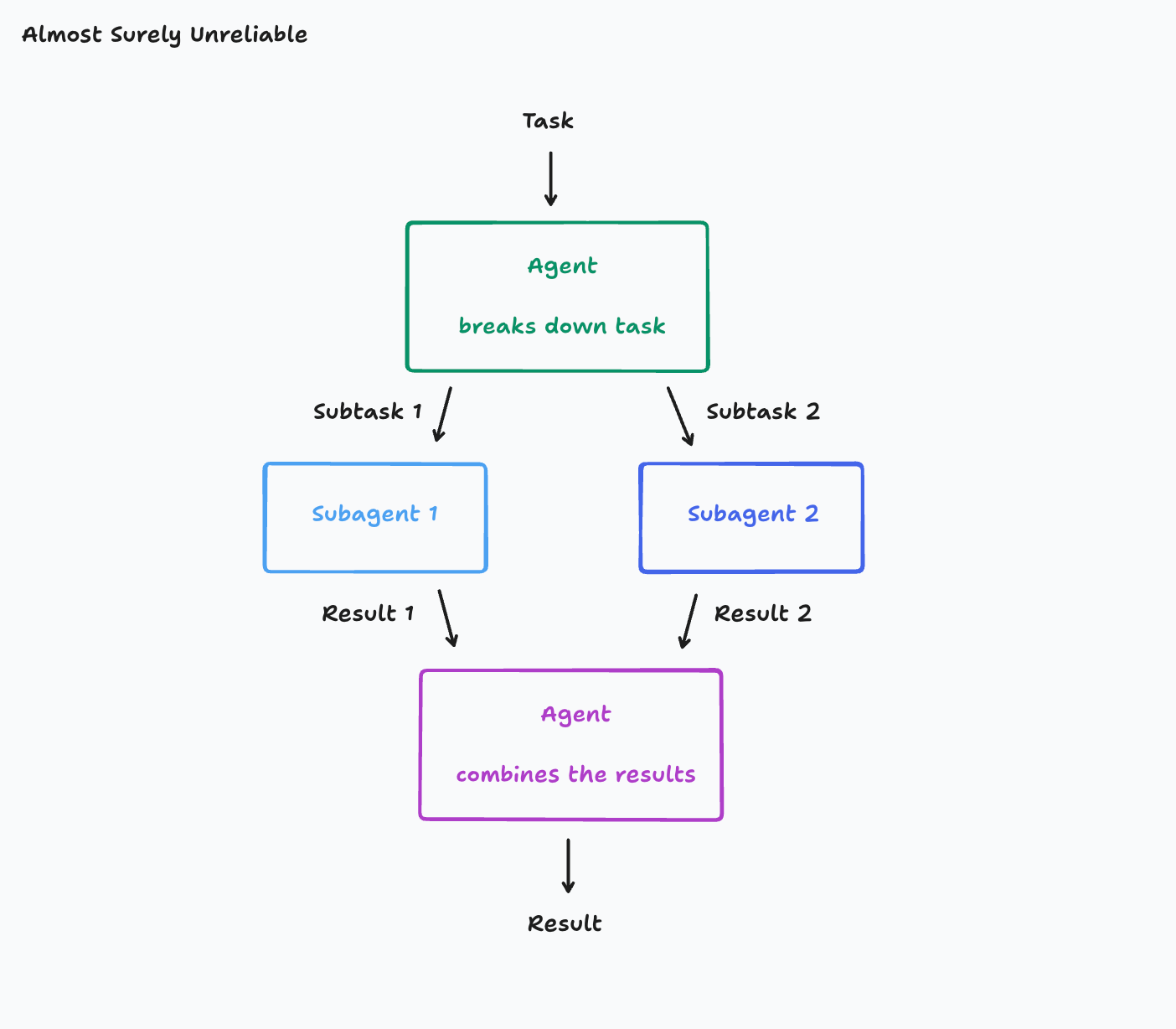
这是一个诱人的架构,特别是在处理具有多个并行组件的任务领域时,然而它也非常脆弱,根本在于 缺乏统一上下文导致认知偏差,举个例子:假设你的目标是构建一个 Flappy Bird 克隆游戏。你将任务拆解为两个子任务:
- 子任务 1:构建带有绿色水管和碰撞检测的背景;
- 子任务 2:实现一个可以上下移动的鸟。
听起来很合理。但如果第一个子智能体误解了你的意图,搞成了一个看起来像《超级马里奥》的横版背景;第二个子智能体虽然生成了一只鸟,但外观不符合游戏风格,动作也完全不像原版游戏——那么你就会发现最终整合这些子模块的 agent,面对的不是“组装”,而是“善后”。
这个例子虽然简单,但它揭示了一个深层次的问题:现实任务中的细节往往非常复杂,而这些细节在子任务划分和传递过程中极易被误解或丢失。
也许你会想,“那我把原始任务也一起传给所有子 agent,不就好了?” 理论上说得通,但实际中却没那么简单。因为:
- 在真实系统中,agent 与用户的对话往往是多轮交互;
- 它还可能调用多个工具,逐步推理出任务的拆解方式;
- 而任务上下文中,哪怕是一个微妙的工具调用或一句对话,也可能极大影响每个子任务的理解方式。
因此,仅仅传递原始任务描述远远不够。要实现真正的多智能体协作,必须构建一个机制,让所有 agent 共享“完整的、实时更新的上下文轨迹”。
Principle 1:Share context#
Share context, and share full agent traces, not just individual messages
让我们再对代理进行一次修订,这次确保每个代理都有前一个代理的上下文。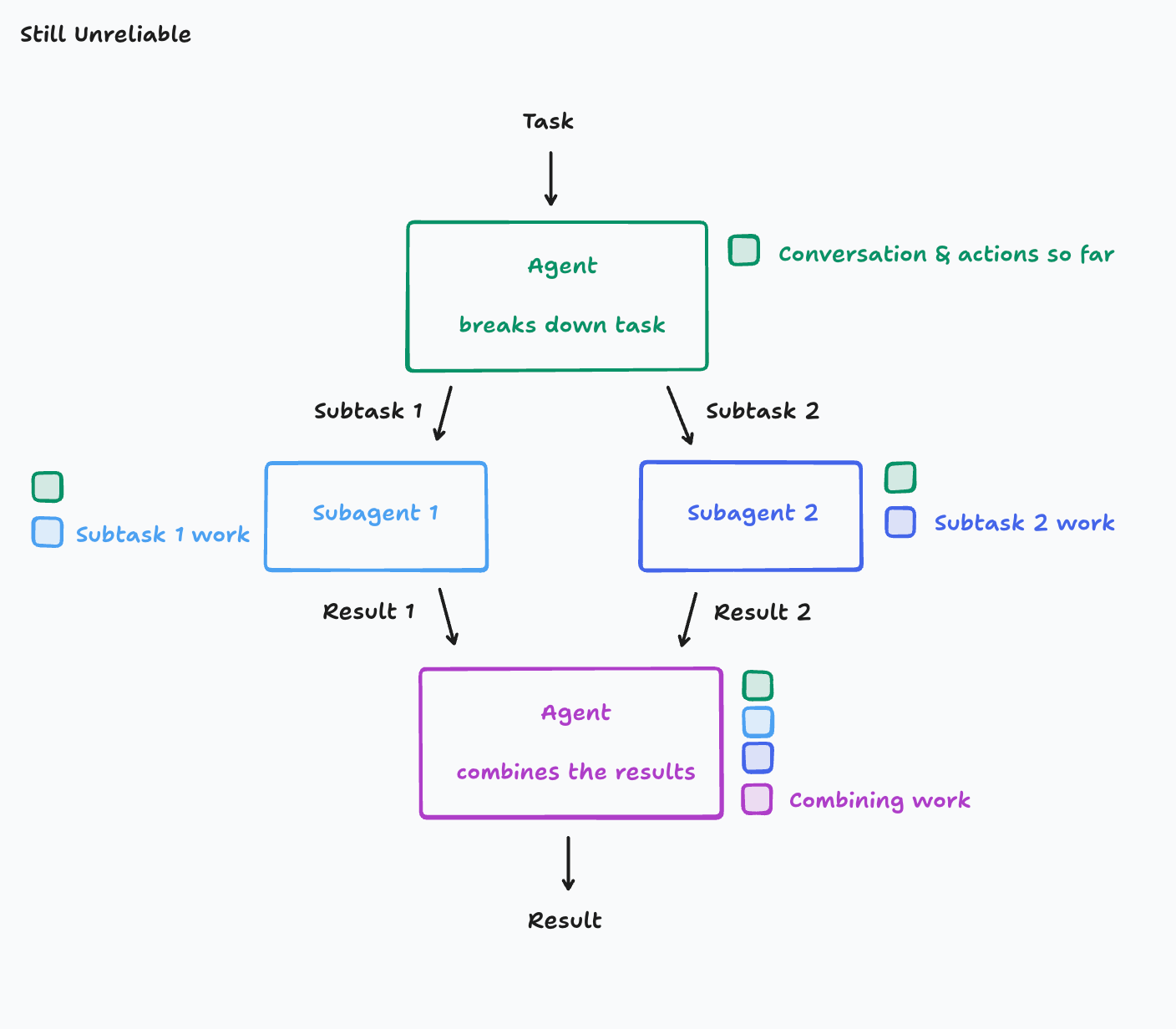
但是很不幸,因为虽然每个子代理都拥有了“原始任务信息”,但他们仍然彼此看不到对方的决策过程,也就是说:他们的行为是基于各自不同、甚至相互矛盾的前提假设。这种信息割裂会直接导致产出不一致,影响最终整合。
Principle 2:Actions carry implicit decisions#
Actions carry implicit decisions, and conflicting decisions carry bad results
即使我们解决了上下文共享的问题,仍有另一个容易被忽视的陷阱:每个 agent 的行为其实都在表达它对任务的某种理解与假设。如果这些假设彼此不一致,最终产出的内容也必然彼此冲突。即没有协调和对齐。
单线程线性 Agent#
作者提出一个重要观点:默认应该排除任何不遵循这两个原则的 agent 架构。 遵循这两个原则最简单的方法就是使用单线程的线性代理
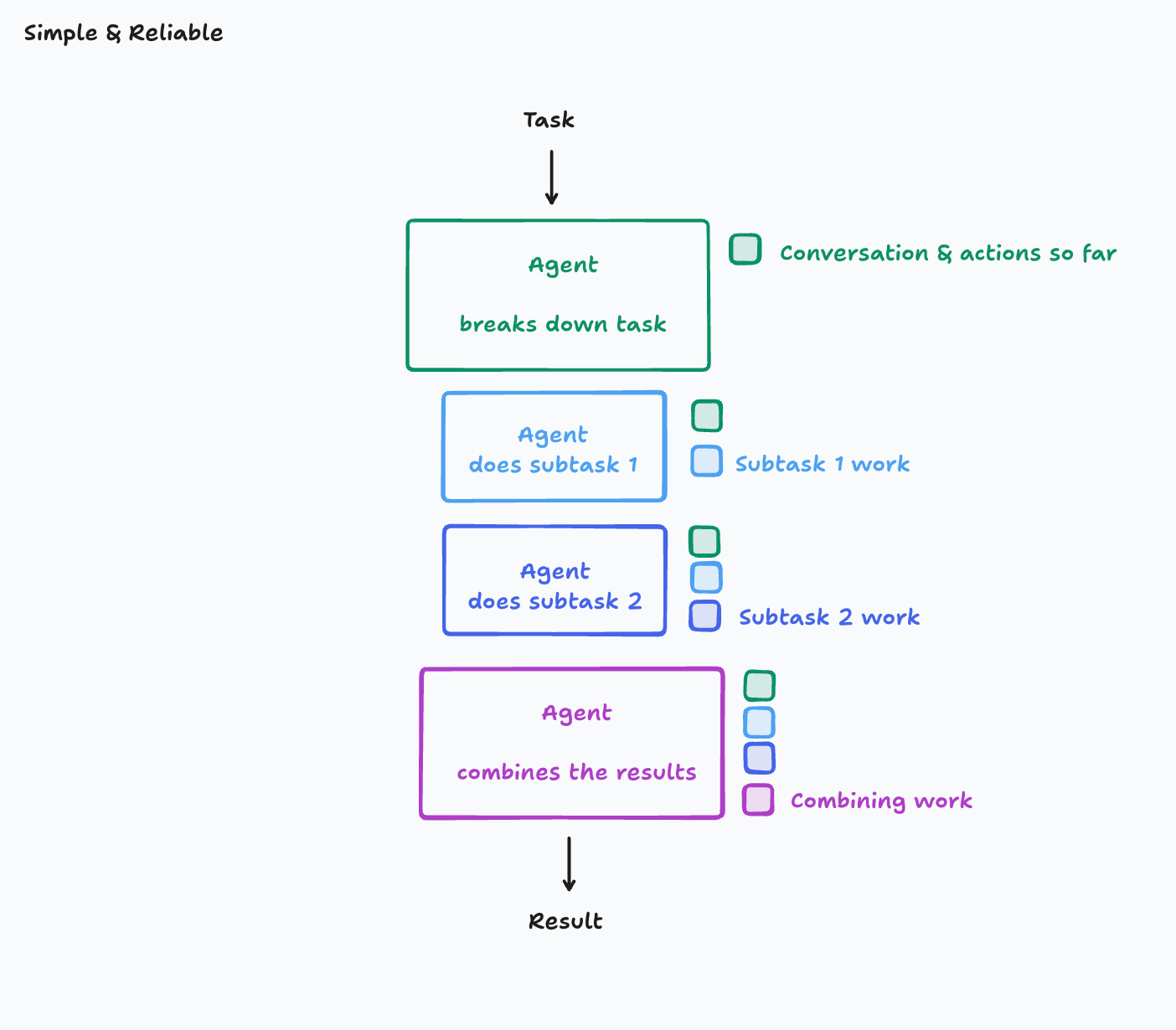
在这个架构中上下文是连续的,但是对于包含大量子任务的复杂任务,上下文窗口可能会溢出。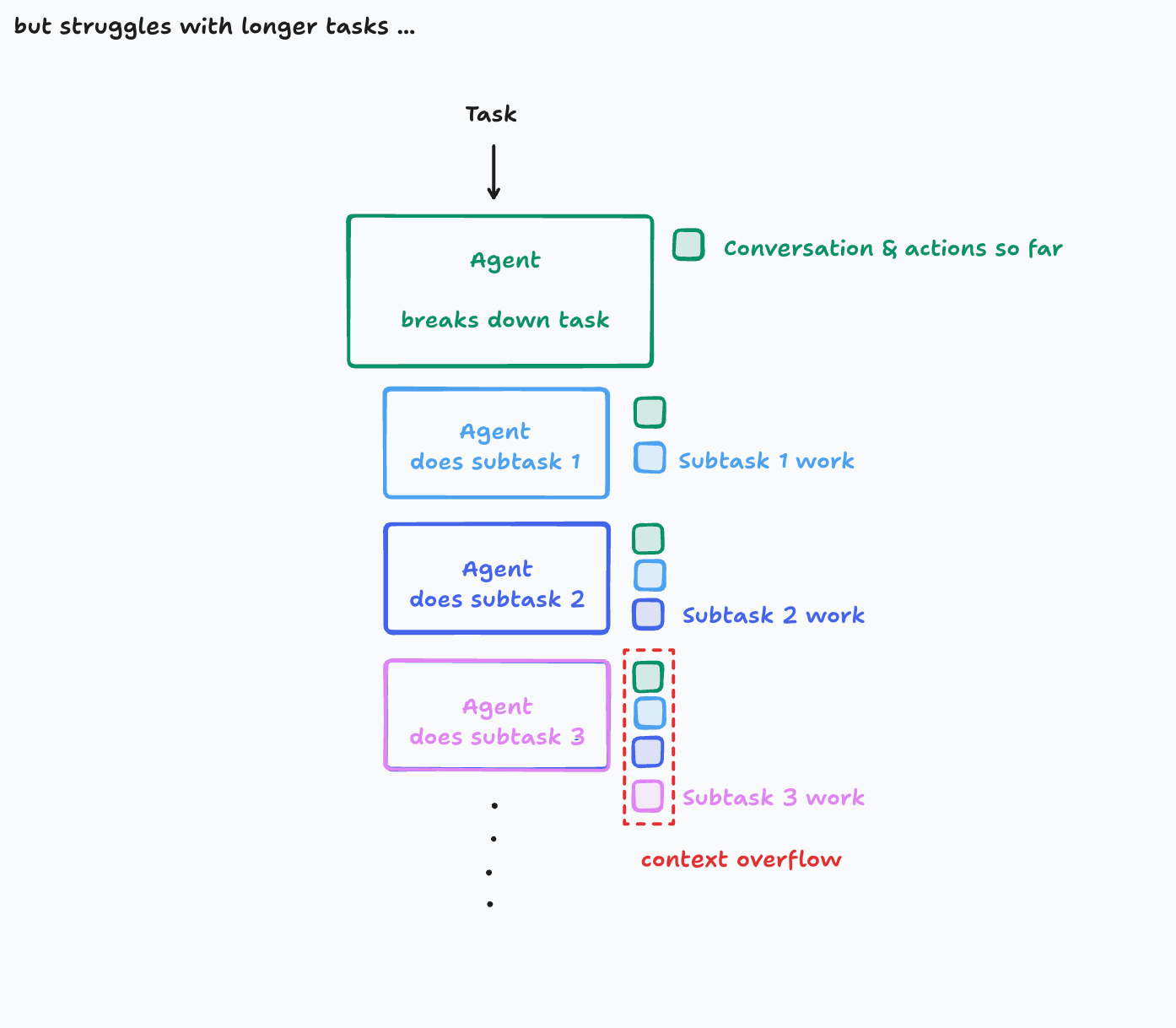
如果你面对的是持续数小时或更长生命周期的复杂任务,有几种可能架构
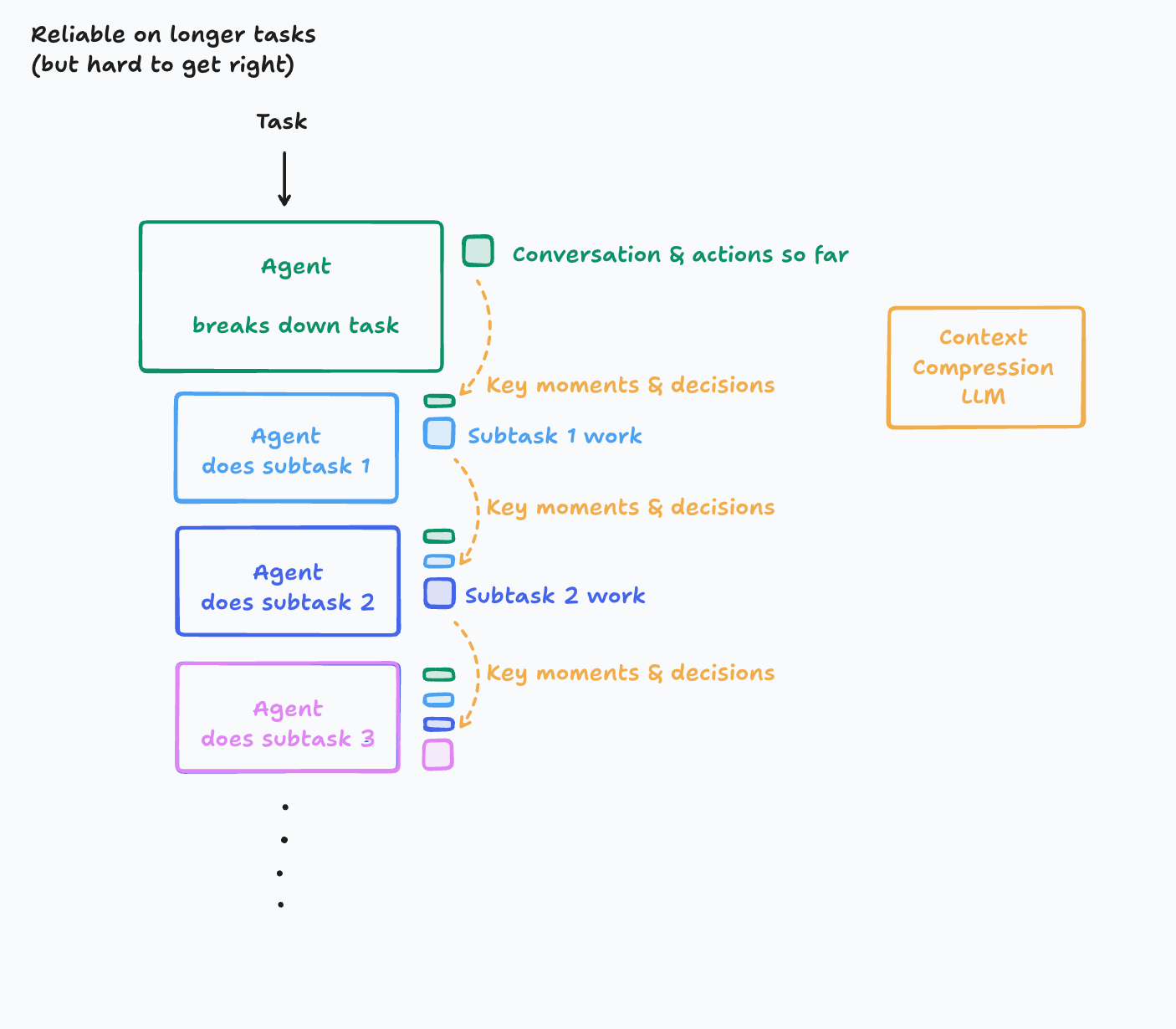
上下文管理器(Context Manager)
工作备忘录和知识协调器
- 追踪 agent 的行为轨迹(任务划分、工具调用、输出结果等);
- 按阶段维护任务状态与关键信息;
- 动态组织上下文,供主 agent 或子 agent 查询调用;
- 上下文管理器可以是一个独立的智能体,专门处理上下文的存储和更新。
压缩型 LLM(Compression LLM)
使用一个专门的 LLM 来压缩和总结上下文信息,负责生成结构化摘要
- 将智能体的整个“行动轨迹 + 对话历史”压缩成关键事件、决策和要点。
- 这种方式可以有效减少上下文窗口溢出的问题,同时 保留关键决策、事件与依赖信息
一些实践#
理想状态下,每一个 agent 行动时都能“看到一切”——包括系统历史、其他智能体的决策、上下文状态等。但现实中,我们受到上下文窗口限制、性能权衡、交互复杂度等因素制约,不可能做到完美感知。这就需要你根据所需的系统可靠性水平,在架构复杂度上做出选择。
- Claude Code 的子代理机制:不并行、不冲突
- 子代理从不与主代理并行运行
- 子代理的职责仅限于回答明确问题,不编写代码
- 子代理的工作不保留在主代理上下文历史中,避免上下文溢出
- Edit‑Apply 模式:复杂协作的失败案例
- 在 2024 年,许多模型在代码编辑任务上表现不佳。一种常见的做法是“编辑-应用模型”:大模型生成 markdown 格式的代码编辑说明;小模型根据该说明实际执行修改。
- 看似分工明确,实则隐患重重。最常见的问题是:小模型误解大模型的意图,即使是最轻微的表述歧义,也可能导致完全错误的修改。
- 现在更常见的做法是:由一个模型一次性完成编辑决策与应用行为,从根源上避免语义脱节。这正是 Principle 2 所强调的核心问题:行为背后隐含的决策,如果被拆散,就容易发生误解与冲突。
- 多智能体协作:看似强大,实则脆弱
- 我们人类在面对冲突时,会主动交流、达成共识(如两个工程师因合并冲突对话协商)。然而,现阶段的智能体尚不具备长上下文中的高质量“共识对话”能力。
- 作者认为,这类问题在未来会随着单线程 agent 更善于与人沟通而自然改善,一旦上下文表达与理解能力足够强大,真正高效的并行协作也就水到渠成了。